
#ValueLeap with PDF Reader Utility – Stratus Driving Innovation with Automation
#ValueLeap with PDF Reader Utility – Stratus Driving Innovation with Automation
By Bhanu Regulagedda & Garima Goel
What are PDF documents?
PDF documents are small-sized, extremely self-assured files. Almost all industries use PDFs for processing their files. The reason being widely used because of the distinctive feature of preserving format nonetheless of the tool used to access PDF files. In our day-to-day life all our invoices, official documents, contractual documents, boarding pass, bank statements, etc. are usually in PDF format.
In this blog, we will delve into Selenium testing of PDF files and how we have designed a solution to handle a PDF document using test automation.
Problem Statement:
With any Insurance Product after successful transactions in the system, we get legal and policy documents generated which are downloaded and verified with a base template along with the manual authentication of the dynamic content like policy number, account number, insured name, address of the policyholder, coverages & premiums etc.
This brings in heavy human work for the Business Users supporting the System including Underwriters, Adjusters etc.
Implemented Solution:
We have designed a solution using PDF Box jars. Before we start, we would take a base template of the document and place it in project resources folder. In our selenium automation test scripts, we would perform related transactions and download the document PDF to a particular location in the machine.
Once we have both the PDF’s we first take the base template and load it to the code using Java/Python. Then we use string libraries of the programming language used in the project to split the content based on the regular expressions to differentiate the dynamic and static content and store static content to a variable and all dynamic data will not be stored but the location of the dynamic data will be identified and stored.
We repeat the same procedure for the document downloaded from <X–Center> after successful transaction. We will store the static content to a variable and all other dynamic content location is stored in the variables.
Now we have both the sample and actual data and using the java/python assert libraries we would assert for the variables for the correctness of the static content and the position of the dynamic content.
Understanding Proposed Architecture:

#ValueLeap – Business Value Delivered
- PDFs/User documents must always be incorporated with accurate details, and it must be ensured that the information provided is verified. Our PDF Reader Utility helps provide seamless automated verification of the documents generated.
- Validating and verifying the documents could be easy when done manually but it poses a major time-related challenge when validating multiple documents in a day. Automating this validation process using our PDF Reader Utility will help in reducing the time challenge for the Business Users and the saved time can be utilized with other tasks bringing efficiencies and higher productivity levels with the team.
- Using PDF Reader Utility will reduce human error(s) during documents authentication ensuring accuracy and positive policyholder feedback along with regulatory compliance.
Meet the Authors


Garima Goel
Associate SVP, Program Delivery, Stratus Global Technology Services

Case Study – How Stratus continues to drive Value and Improvement with its Clients for Regulatory Services
Case Study – How Stratus continues to drive Value and Improvement with its Clients for Regulatory Services
By Meyvannan Varadharajan & Garima Goel
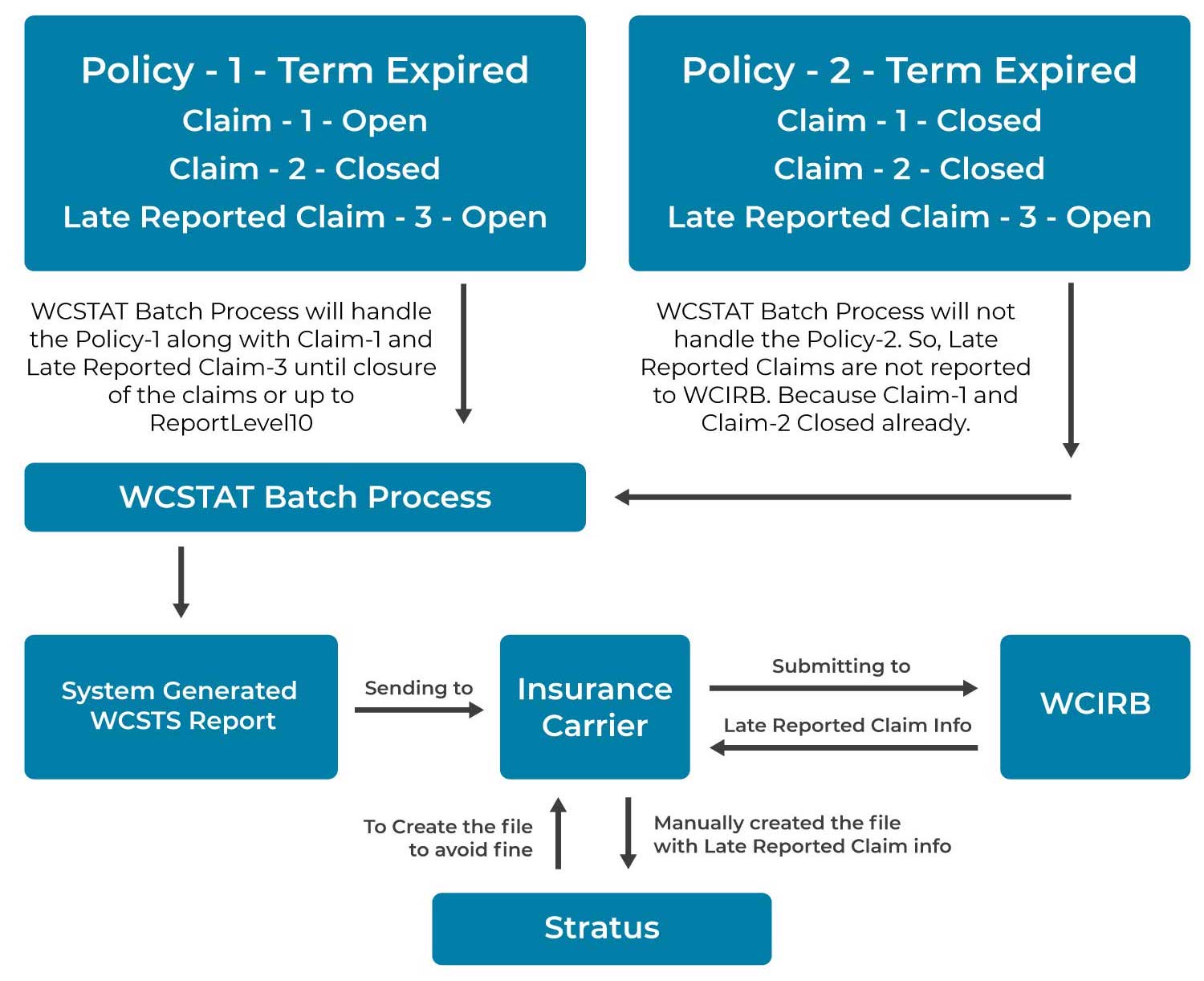
What are Late Reported Claims?
Adjusters creating claims on already expired/closed WC policy periods are termed as Late Reported Claims.
Problem Statement:
The Late Reported Claims which are created on a closed or expired WC policy period with no prior claim in open status for that particular policy period are not being reported to WCIRB bringing regulatory incompliance. In these situations, WCIRB expects the claims to be reported and filed with the Bureau via WCSTAT Report.
Since the automated WCSTAT batch is unable to pick up these Late Reported Claims for reporting, this has been causing manual work for the team to prepare correction files so that the Late Reported Claims could be submitted to WCIRB on time avoiding incompliances.
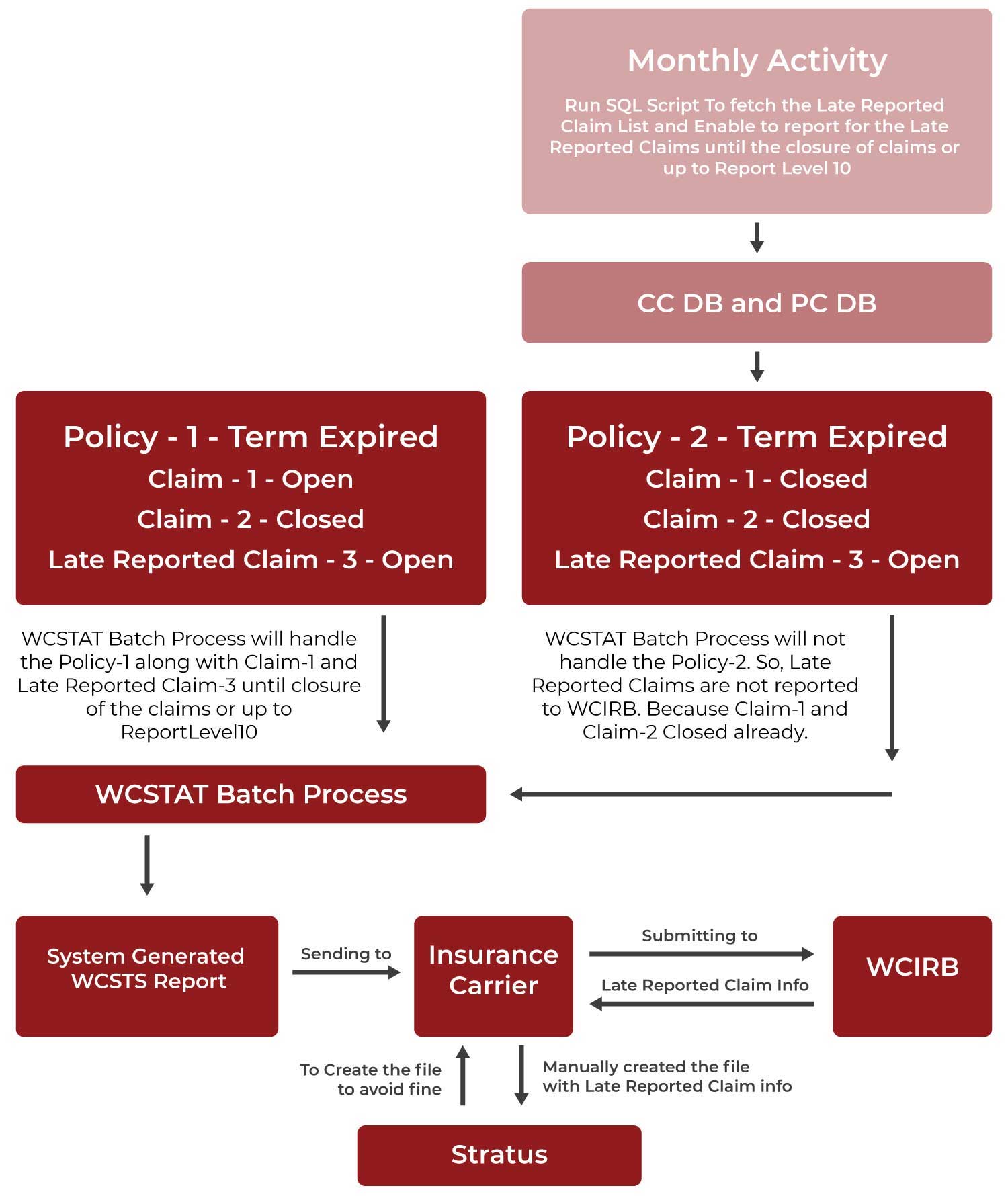
Proposed Solution:
After detailed root cause analysis and investigation, we designed Script 1 to identify the LRCs every month. Followed by running Script 2 to update the “Flag Variable” and Report Level for the closed Policy period where the Late Reported Claim has been filed. This process of Script runs will take care of reporting the late reported claims every year until its closure or up to 10th Report Level to WCIRB.
Understanding As-Is Architecture/Flow:
Understanding Proposed Architecture/Flow:
#ValueLeap – Business Value Delivered
- All claims logged in the GW system are getting reported to WCIRB via WCSTAT files without failure.
- Ensuring Regulatory Compliance.
- Avoiding manual work of preparing correction files to report LRCs.
- Reducing the Insurance Carrier’s error count in the Quarterly Business Review with the Bureau.
- Delivering Happy Client!
Meet the Authors

Garima Goel
Associate SVP, Program Delivery, Stratus Global Technology Services

Containerization: can it be a differentiator for IT companies’ carbon neutrality pledge
Containerization: can it be a differentiator for IT companies’ carbon neutrality pledge
By Vijay Singh Yadav, VP of Applications at Stratus
Context
As countries across the world have committed to The Paris Agreement to combat global climate change, Information Technology (IT) companies on their part have pledged to reduce their carbon footprints. A big part of IT company’s emissions come from the consumption of electricity required to run their offices and data centers. To achieve carbon neutrality, organizations have to address the issue from three dimensions: reducing energy consumption through energy efficiency, transitioning to renewable energy sources and offsetting emissions that are beyond its control.
While transitioning to renewal energy can be achieved by reducing its dependence on fossil-fuel-dominated grid power and switching to solar power plants or other green energy solutions, reducing energy consumption is a key challenging area which should be dealt with utmost care to reduce the carbon footprints without impacting the operations of an IT organization and their customers. As mentioned above, data centers are the key contributors to the electricity consumption when playing their role to process, store and communicate the data via information services provided by the applications hosted on the servers. This article discusses the various hosting options and whether they can make a difference in IT companies’ goal to achieve carbon neutrality.
Data Centers
Data centers (Corporate data centers or Cloud data centers) utilize different information technology (IT) devices to provide IT services, all of which are powered by electricity. Servers provide computations and logic in response to information requests, while storage drives house the files and data needed to meet those requests. Network devices connect the data center to the internet, enabling incoming and outgoing data flows. The electricity used by these IT devices is ultimately converted into heat, which must be removed from the data center by cooling equipment that also runs on electricity.
On average, servers and cooling systems account for the greatest shares of direct electricity use in data centers, followed by storage drives and network devices. Some of the world’s largest data centers can each contain many tens of thousands of IT devices and require more than 100 megawatts (MW) of power capacity—enough to power around 80,000 U.S. households (U.S. DOE 2020).
While electricity consumption of cooling systems can be addressed by migrating to large cloud- and hyperscale-class data centers, which utilize ultra-efficient cooling systems (among other important efficiency practices) to minimize energy use or building data centers near the Arctic for natural cooling and others beside huge hydroelectric plants in the Pacific Northwest (as some of the Cloud providers have done it), the challenge remains for the IT devices’ electricity consumption.
Several improvements have been done to make the IT devices energy efficient, particularly servers and storage drives have improved substantially due to steady technological progress by IT manufacturers. However effective use of these IT devices is required to contain the electricity consumption, especially for servers which host IT applications and need optimization to ensure that they are not underutilized. To better utilize the servers’ capability, concept of server virtualization is being used which enables multiple applications to run on a single server.
Server virtualization
Server virtualization is the process of dividing a physical server into multiple unique and isolated virtual servers by means of a software application. Each virtual server can run its own operating systems and applications independently. It is a cost-effective way to provide IT application hosting services and effectively utilize existing resources in IT infrastructure. Without server virtualization, servers only use a small part of their processing power. This results in servers sitting idle because the workload is distributed to only a portion of the network’s servers. Data centers become overcrowded with underutilized servers, causing a waste of resources and power.
Server virtualization has mainly three components –
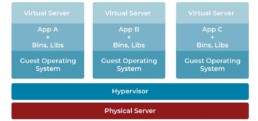
- A host machine, which is the physical server hardware where virtualization occurs
- Virtual servers, which contain the assets that are abstracted from a traditional server environment
- A hypervisor, which is a specialized software that creates and maintains virtual machines and can be run natively on bare metal servers or hosted on top of an existing operating system
This process increases the utilization of resources by making each virtual server act as a physical server and increases the capacity of each physical machine to host multiple applications. However, it still does not guarantee the better utilization of servers as server virtualization has just shifted the problem of underutilization from physical server to virtual servers. Virtual servers still have to be with fixed capacity and sized based on the IT application’s peak load needs. What if IT application usage is not as much as it was anticipated or if there are fluctuations in usage. In that case, virtual servers may also be sitting ideal based on the application load. As physical servers cannot be scaled up or down automatically, they are most likely either over-provisioned or under-provisioned.
Cloud providers have tried to solve this problem by providing server compute resources on an elastic model that can scale up or down as needed. With Cloud server virtualization, Cloud vendors use server virtualization to abstract large pools of compute resources within data centers to be consumed by end users. Cloud services provide users with access to virtualized server capacity but not to the physical hardware itself. For example, Amazon Web Services (AWS) might have tens of thousands of physical servers in a data center, but end users do not get access to the actual physical server hardware. Instead, the EC2 (Elastic Compute Cloud) service offers cloud server virtualization with different sizes and configurations of virtual machine cloud instances. However, question remains the same what if sizing of the virtual machine has not been done appropriately and it is still underutilized. While Cloud provides the flexible infrastructure that will scale up or down based on resource requirements such as CPU or memory utilization, can IT applications support this elastic model. The answer depends on whether IT applications can be abstracted like server virtualization and scaled up or down as needed. If applications can be boxed, then multiple instances of the same application or multiple applications can be deployed on the same physical server and share the compute resources with elasticity. This concept of boxed application is called Containerization and when combined with container orchestration services can effectively utilize the server resources and scale up or down automatically.
Containerization
Containerization is about packaging an application, including all of the bins and libraries it needs to run correctly, into a container. Application containerization is an operating system level virtualization method used to deploy and run applications without launching an entire virtual machine for each app. Multiple isolated applications or services run on a single host and access the same operating system kernel. Containers can work on bare-metal systems, cloud instances and virtual machines.
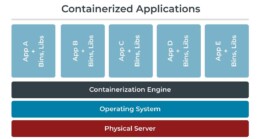
The architecture for application containerization is fundamentally different from that of virtualization, especially in that it does not require a hypervisor. Containers also do not run their own individual instances of the operating system. They only house the application code along with its dependencies (bins, libraries, etc.). A containerization engine software sits between the containers and the host operating system, and each container on the machine accesses a shared host kernel instead of running its own operating system as virtual machines do.
The principal benefit of application containerization is that it provides a less resource-intensive alternative to running an application on a physical server. This is because application containers can share computational resources and memory without requiring a full operating system to underpin each application. Containers take less space than virtual machines (container images are typically tens of MBs in size), can handle more applications and require fewer virtual machines and operating systems. But the answer to the question of how containers are going to optimize the utilization of server resources lies with container orchestration services.
Container orchestration is all about managing the lifecycles of containers i.e. automating the deployment, management, scaling, networking and availability of containers. The automatic scaling provides the capability to scale up or down based on the CPU or memory utilization. Automatic scaling ensures that application is always available and has enough resources provisioned to prevent performance problems or outages. And in turn ensures that infrastructure resources are utilized judicially thus optimizing the energy consumption. There are many container orchestrations tools available like Kubernetes, Amazon ECS (Elastic Container Service)/EKS (Elastic Kubernetes Service) etc. which provide autoscaling capability. There are two ways to implement the container based autoscaling –
Serverless Computing – is a concept where application team doesn’t need to procure virtual machines or physical servers. They only need to specify the memory and compute resources required for their application and the serverless computing provider takes care of the infrastructure needs. For example, AWS offers a fully managed and scalable container infrastructure called Fargate. AWS Fargate is a serverless compute engine for containers that works with container orchestration tools, Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS).
So, application team just need to containerize their application and deploy using ECS or EKS on AWS Fargate. When configuring ECS or EKS, application team has to specify the memory and compute resources for their application and also autoscaling policy. Allocation & Autoscaling of infrastructure resources is taken care by Fargate, and Availability & Autoscaling of container is taken care by ECS or EKS. This way application doesn’t need to have dedicated physical server or virtual machine and serverless computing provider has flexibility to host multiple applications, thus optimizing the infrastructure resources’ utilization.
Server based computing – is when application team wants to self-manage the infrastructure needs of their application. So, in this case application team has to size the memory and compute resources of physical server or virtual machine. Though sizing of physical server or virtual machine can lead to the issue of underutilization or overutilization, the autoscaling capability provided by container orchestration tools can minimize the impact to some extent. Let’s take an example of deploying ‘App A’ to Cloud provided virtual machine and how autoscaling can minimize the infrastructure resources’ wastage.
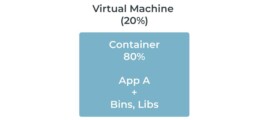
- First finalize the server resources needed by application to handle the user traffic during normal business hours.
- Then, size the virtual machine considering that 20% of the server resources will be used for virtual machine system operations and 80% available for container.
- Using container orchestration tool,
- configure a cluster with Auto Scaling policy for virtual machine
- configure container orchestration service with Auto Scaling policy for containers
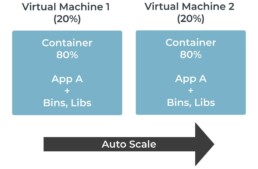
- Define the scaling policy that,
- if server utilization increases above 80%, add a new container and virtual machine to the cluster
- if server utilization drops below 40%, remove the additional container and virtual machine
This way with container orchestration service, virtual machines can be provisioned with just enough resources for daily use and not for peak traffic. Container orchestration tools like Kubernetes, Amazon ECS/EKS etc. provide both Cluster & Container auto scaling capabilities.
Conclusion
Carbon neutrality is a vast topic and has many dimensions but when looked at from IT companies’ perspective, can be centered around their IT operations. And the IT devices are the most significant part of their operations as well as the major contributors to energy consumption. Hence if IT companies want to reduce their carbon emission, they must optimize the electricity consumption of their IT devices. IT devices are used by software applications to perform business functions and therefore usage of IT devices depend on software applications’ infrastructure need. As world is moving towards digitizing each & every task, the usage of software applications is increasing day by day and in turn demanding more infrastructure resources. Therefore, optimizing infrastructure resources is the need of the hour and containerization looks to be one of the solutions which can make a difference for IT companies to achieve their carbon neutrality target.
While containerization is known for enabling automated deployment of applications as portable and self-sufficient containers that can run in the Cloud or On-premises, it also provides a way to optimize the usage of infrastructure resources when used with automatic scaling. As described above, containerization orchestration not only ensures the availability of the application but also provides the capability to scale up or down based on the application load. There are millions of IT applications and if every application infrastructure is designed to have just enough resources required for an application most of the time and if every organization do their bit, it can impact the overall energy consumptions of IT systems. Therefore, an effort to containerize the applications will reap benefits both from cost perspective as well as carbon neutrality and IT companies should look at it as one of the tools to reduce carbon emissions.
References
https://energyinnovation.org/2020/03/17/how-much-energy-do-data-centers-really-use/
https://davidmytton.blog/how-much-energy-do-data-centers-use/
https://www.docker.com/resources/what-container
https://www.sumologic.com/glossary/application-containerization/
https://unfccc.int/climate-action/momentum-for-change/climate-neutral-now/infosys
https://phoenixnap.com/kb/what-is-server-virtualization
https://www.serverwatch.com/virtualization/server-virtualization/
https://blog.newrelic.com/engineering/container-orchestration-explained/
https://cloudonaut.io/scaling-container-clusters-on-aws-ecs-eks/
https://aws.amazon.com/blogs/compute/automatic-scaling-with-amazon-ecs/
https://aws.amazon.com/fargate