
Stratus is Pleased to Announce a New Partnership with and Investment by New Heritage Capital
Stratus is Pleased to Announce a New Partnership with and Investment by New Heritage Capital
NEW JERSEY, April 4, 2023 – Stratus Technology Services (“Stratus” or the “Company”), a global provider of specialized technology services and solutions, is pleased to announce a new partnership with and investment by New Heritage Capital (“Heritage”), a Boston-based private equity firm focused on partnering with high-growth, founder-owned business. The investment was structured using Heritage’s Private IPO® solution, which leaves operating control in the hands of current Stratus management while providing the financial flexibility to accelerate future growth.
Founded in 2001, Stratus offers a suite of specialized technology services and solutions such as staffing services, managed services including production support, as well as project delivery, among others, through managed and consulting delivery models. Stratus has developed a specialized expertise in the unique requirements of clients in the P&C insurance space, specifically users of Guidewire, a leading Insurance Management Platform. Stratus has a global reach with over 550 employees worldwide.
Powered by this investment partnership with New Heritage Capital, Stratus will continue to expand within the P&C market while also strategically investing in additional technologies and solution offerings to better service their customer base. Stratus expects to continually increase scalability while maintaining a quality-driven and customer-first approach.
Jamie Raymond, Co-Founder and CEO of Stratus, said, “I am incredibly proud of what the Stratus team has achieved to-date and excited about what the future holds. We have big goals of growing our delivery team and expanding our capabilities, including cloud implementations and migrations. Engaging a partner like New Heritage, who has significant experience scaling businesses like ours, will help us achieve the near and long-term objectives of Stratus.”
Steve Damen, Co-Founder and Partner of Stratus, added, “We have grown to where we are today through an unwavering commitment to our clients and our people. The New Heritage model allows us to preserve that commitment and the Stratus culture that makes us who we are.”
Kyle Veatch, Principal at Heritage, said, “We are big believers in the Stratus team and their value proposition. They are true technology and P&C experts and we see a tremendous opportunity to continue to expand what they offer to existing and new clients.”
RVR Consulting served as the exclusive financial advisor to Stratus Technology Services.
About Stratus Technology Services
Stratus is a global provider of specialized technology services, including application managed services, implementation, and consulting. Founded in 2001, Stratus is entrusted by its clients to implement, manage, develop, and advise on mission critical technology systems and projects. Stratus provides services to clients across a broad range of industries and has developed an expertise for the unique needs of clients in the P&C insurance industry, with strong capabilities supporting Guidewire, a leading Insurance Management System. Stratus is one of just a few Guidewire Cloud Specialized providers in the U.S.
About New Heritage Capital
New Heritage Capital is a Boston-based private equity firm with a twenty-year history of partnering with growing, middle market, founder-owned businesses. With its innovative investment structures like the Private IPO®, Heritage provides founders with a combination of liquidity and growth capital while allowing founders to maintain control of their business. With decades of experience at managing growth, Heritage gives its partners the strategic, operational and financial guidance to help its companies reach their growth objectives.

Stratus Achieves Guidewire PartnerConnect Program Cloud Specialization
Stratus Achieves Guidewire PartnerConnect Program Cloud Specialization

SHREWSBURY, NJ, Sep. 1, 2022 — Stratus Technology, a global technology consulting firm, today announced that it has achieved the Guidewire PartnerConnect specializations: Cloud Ready AMER. Stratus, is a Guidewire PartnerConnect Consulting partner at the Select level and works with Guidewire in North America.
Specializations are both regionally and globally based and require partners to demonstrate skills, knowledge, and competency in a particular Guidewire product or solution area. The achievement of specializations enables insurers to have more clarity and insight into which partners have proven capabilities in a region. In addition, partners with specializations can better promote their capabilities across Guidewire products and solutions.
“We congratulate Stratus Technology on achieving the Cloud Ready AMER specialization. We are pleased to recognize their expertise and proven capabilities and look forward to continuing our work together to contribute to the success of our mutual customers,” said Molly Black, Senior Director, Partner Programs and Enablement, Guidewire.
“Stratus is thrilled to have been awarded Cloud Ready Specialization for the Americas! Achieving this milestone further demonstrates our commitment to continually invest in solutions that will enable carriers to transform their technology landscape and unlock business value through the enhanced features that Guidewire Cloud brings. We look forward to supporting our customers every step of the way throughout their journey,” said Britt Bahar, Chief Sales Officer, Stratus.
Rafael Moreira, Senior Vice President of Global Delivery, Stratus, adds, “In order to stay ahead of the projected growth of Guidewire Cloud while meeting the needs of our customers, our global Delivery organization has made significant investments to ensure we continually upskill our teams and have them complete the Cloud Certification path. Ensuring our customers have access to the thought-leadership of experienced and certified resources to help ensure a smooth transition to Guidewire Cloud is our top priority.”
Please find more information about Guidewire specializations on the Guidewire website here.
With more than 20 years of insurance experience, Stratus has provided Guidewire specific solutions since 2013 and has a demonstrated track record of partnering with P&C insurers in deploying, customizing, enhancing, and maintaining their investment in Guidewire technology and its integrations.
Powered by their global team of Guidewire subject matter experts, Stratus offers scalable solutions which include Implementations, Upgrades, Managed Services, and Project-based services for Guidewire’s InsuranceSuite, data, and analytics, digital and Guidewire Cloud products. Flexible engagement models are supported by Stratus’ 24/7 delivery center in Hyderabad, India which offers scalable and cost-effective solution models.
Stratus’ core engagement team develops customized solutions driven by in-depth customer understanding, industry best-practices and extensive Guidewire product knowledge with the commitment to provide impactful results to consistently drive business value and long-term success.

Stratus Earns 2022 Great Place to Work Certification™
Stratus Earns 2022 Great Place to Work Certification™
 Stratus is proud to be Certified™ by Great Place to Work® in the U.S. This prestigious award is based entirely on what current employees say about their experience working at Stratus, which ranked 25 points higher than the average U.S. company.
Stratus is proud to be Certified™ by Great Place to Work® in the U.S. This prestigious award is based entirely on what current employees say about their experience working at Stratus, which ranked 25 points higher than the average U.S. company.
Great Place to Work® is the global authority on workplace culture, employee experience, and the leadership behaviors proven to deliver market-leading revenue, employee retention and increased innovation.
“Great Place to Work Certification™ isn’t something that comes easily – it takes ongoing dedication to the employee experience,” said Sarah Lewis-Kulin, vice president of global recognition at Great Place to Work. “It’s the only official recognition determined by employees’ real-time reports of their company culture. Earning this designation means that Stratus is one of the best companies to work for in the country.”
“We are thrilled to become Great Place to Work-Certified™ as we consider employee experience a top priority every day,” said President and CEO, Jamie Raymond. “We owe our continued success to our team of dedicated employees at Stratus. We celebrate and thank them for all they do to earn this incredible recognition.”
Earlier this year, Stratus also earned Great Place to Work Certification™ in India.
According to Great Place to Work research, job seekers are 4.5 times more likely to find a great boss at a Certified great workplace. Additionally, employees at Certified workplaces are 93% more likely to look forward to coming to work, and are twice as likely to be paid fairly, earn a fair share of the company’s profits and have a fair chance at promotion.
About Stratus
Stratus Technology Services, LLC, is a provider of innovative workforce and information technology services and solutions that are completely focused on client success. At Stratus, it is our uncompromising commitment to extraordinary people implementing defined and proven methodologies, that allows for the delivery of the right solutions for our clients’ critical business needs every time.
Our model of service excellence has provided for timely, cost-effective and focused solutions for large and small clients on a nationwide basis since 2001. At Stratus, we are a leader in the new economy, which demands strategic partners who are agile, focused and completely engaged.
About Great Place to Work Certification™
Great Place to Work® Certification™ is the most definitive “employer-of-choice” recognition that companies aspire to achieve. It is the only recognition based entirely on what employees report about their workplace experience – specifically, how consistently they experience a high-trust workplace. Great Place to Work Certification is recognized worldwide by employees and employers alike and is the global benchmark for identifying and recognizing outstanding employee experience. Every year, more than 10,000 companies across 60 countries apply to get Great Place to Work-Certified.
About Great Place to Work®
Great Place to Work® is the global authority on workplace culture. Since 1992, they have surveyed more than 100 million employees worldwide and used those deep insights to define what makes a great workplace: trust. Their employee survey platform empowers leaders with the feedback, real-time reporting and insights they need to make data-driven people decisions. Everything they do is driven by the mission to build a better world by helping every organization become a great place to work For All™.
Learn more at greatplacetowork.com and on LinkedIn, Twitter, Facebook and Instagram.

A Review Article On How Salesforce Has Changed Worklife Globally
A Review Article On How Salesforce Has Changed Worklife Globally
By Stratus Salesforce COE
 Salesforce is a cloud-based customer relations service provider (or CRM) based in the United States that provides customers with a platform to develop their own applications without following the tough steps that they used to have to follow in the legacy system. Salesforce has defined the ideal way to build a meaningful and lasting bond with its customers by identifying their needs, addressing problems faster, and deploying new apps.
Salesforce is a cloud-based customer relations service provider (or CRM) based in the United States that provides customers with a platform to develop their own applications without following the tough steps that they used to have to follow in the legacy system. Salesforce has defined the ideal way to build a meaningful and lasting bond with its customers by identifying their needs, addressing problems faster, and deploying new apps.
Let’s take a glance at an amazing collection of Salesforce success stories from all around the world.
A working parent with access to childcare in the United Kingdom noticed that many female colleagues in India had dropped out of the workforce in the absence of such options in their country. Her strong desire to enable women to follow their dreams led her to become the CEO of a renowned school and daycare in India.
In the early days of running the school, she and her staff used an Excel spreadsheet to measure business metrics. As the business continued to expand, however, they looked out for an automated solution that could help them – and they found Salesforce. They started using Sales Cloud and Service Cloud for lead management and omnichannel service delivery and noted that the flexibility and ease of use that Salesforce offers has helped drive internal adoption very quickly. With the wide range of resources that Salesforce offers, system administrators could quickly roll out modules for on-the-spot requirements, such as sending out communication to families – which, earlier, had taken as long as 3-4 days – in just a couple of hours. With all lead data consolidated on Salesforce, the team can now target programs effectively, optimize campaign spends, focus on channels that yield more, and enjoy a more data-drive marketing engine.
On the other side, a Company from California that specializes in selling and installing energy efficient products was seeing a plateau in sales due to a lack of proper record maintenance, no accurate data, and loss of internal communication. They began searching for new technology that could help them update their work environment, ultimately leading to profits. By implementing Sales Cloud, Service Cloud, Chatter, Five9 and Genepoint integration, Salesforce has successfully resolved the problem for the client by doing the following and enabling the company to experience profits, value and overall customer satisfaction:
- Created automation to deliver appointments to sales representatives faster with complete access to any required information on demand.
- Migrated the entire marketing and sales departments from paper to a build out of Sales Cloud Lightning with Chatter.
- Integrated Geopoint to provide a 360-degree view of all customer locations while scheduling appointments.
- Built new performance dashboards and reports.
- Integrated the Five9 Dialer inside of Salesforce – configured with screen-pop and business intelligence.
 Next, a bank from Malaysia experienced a massive growth in its customer base, which led to a large increase in support requests, and needed to build a system that could effectively scale and route inquiries. Prior to the project, they had over 10 teams managing various parts of their contact center services, and over 50 different customer support phone numbers. They chose Salesforce as their new platform of choice due to Salesforce’s high potential to scale and innovate, as well as its multi-cloud approach that extends beyond the contact center.
Next, a bank from Malaysia experienced a massive growth in its customer base, which led to a large increase in support requests, and needed to build a system that could effectively scale and route inquiries. Prior to the project, they had over 10 teams managing various parts of their contact center services, and over 50 different customer support phone numbers. They chose Salesforce as their new platform of choice due to Salesforce’s high potential to scale and innovate, as well as its multi-cloud approach that extends beyond the contact center.
The transformation needed to accomplish three things – efficiently manage the contact center, unify customer service channels, and unify their technology platform – all with a focus on improving user experience for customers and agents. By utilizing Omni-Channel, queries are now directed to certain channels for support. The bank incorporated AI, including agent-facing chatbots to offset basic inquiries, to escalate to live agents when appropriate, and to surface answers during customer interaction to reduce case time to resolution. After implementing the Salesforce service, the support channels are now providing nearly two million answers each month.
And finally, a startup company from Indonesia – which had only a single call center in Jakarta – became quickly overwhelmed as thousands of merchants rushed to register on their website, and it created a complicated workflow that required the sales team to manually replicate account data across several back-end systems using spreadsheets.
After implementing Salesforce, they are now using Sales Cloud along with Google Sheets Salesforce, which has helped increase the speed at which the company onboards merchants and hence revolutionized productivity. Sales Cloud provides the speed and agility the team requires to support the company’s exponential growth, and the company plans to use Marketing Cloud to inform its strategic decision-making and help its merchants better serve their customers. Data in Salesforce allows them to see the density of merchants in different areas.
Salesforce’s core value of equality, and its belief that business is the greatest platform for change, will continue to drive the partnerships between the two companies well into the future.
Stratus has joined the Salesforce Consulting and Managed Service Partner programs, where we will focus and aim at creating impactful results and empowering our clients to achieve more with experienced resources, innovative solutions, speed, and efficiency with scalable results. We also strongly believe that this long-term partner relationship will help us deliver value and end-to-end sustainable support to our clients driven by technology and business value.
Authors:
- Sai Sreekar
- Karishma Potnuru
- Monisha E
- Sagar Sonawane
- Niharika Lakkineni

Stratus' Commitment to Corporate Social Responsibility
Stratus' Commitment to Corporate Social Responsibility
At Stratus, we understand our Corporate Social Responsibility (CSR) to do our bit for the society and help people around us who are less privileged and fortunate than us so we can make our ecosystem a better place to live.
Stratus decided and invested to plant trees for Environmental and Economic Sustainability. Every tree planted will not only contribute to the World’s terrestrial biodiversity but also uplifting and supporting the Farmers of our Country enabling them to better earn their livelihood. These will be continued efforts by the Organization generating revenues for the beneficiaries in the rural areas of Telengana and Karnataka! Hence, we partnered with SankalpTaru (https://sankalptaru.org/) and SayTrees (http://www.saytrees.org/) to support create forests and help our Planet.
We are also proud partners with Sayodhya (https://sayodhya.org/), an initiative started in 2010 by a group of women activists working with children at risk. They felt impelled to start this home after witnessing increased incidences of violence against women and their children, leading to destitution, desertion and homelessness. Together, they established a short stay home which is a transit refuge center for women and children who are escaping range of abusive situations-physical, sexual and emotional, who have no social support systems to rely on.


Acid Attacks are the brutal form of violence that undermines the basic rights to any individual under several human rights instruments. Almost 50% of the total survivors of the acid attacks are from vulnerable age group of 1 to 25 yrs., thus making rehabilitation a challenging task to undertake for governments & non-profit organizations Surgeries don’t guarantee a complete cure, because acid can cause skeleton damage or organ failure. Stratus collaborated with Chhanv Foundation (https://www.chhanv.org/) to provide funds for the treatment and surgery of acid attacks survivors to help the brave survivors have a stronger headspace and heal from their traumatic experiences and are also encouraged and taught life skills like cooking, public speaking, soft skills, etc. that can make them independent.

Covid-19 crisis impacted the global economy especially leaving the people from rural areas of India jobless and without food. Shine NGO (www.shinengo.org) started the Rs. 5 Idli campaign providing food to the poor as Covid-19 relief activity, so no one goes to work empty stomach. Stratus has partnered with Shine NGO to support this mission in developing a better society with no hunger and Feed the Needy.

How Stratus Constructs Diversity, Equity, and Inclusion Into Its Culture
How Stratus Constructs Diversity, Equity, and Inclusion Into Its Culture
At Stratus, we are highly focused on a healthy and an open-minded work environment with Diversity, Equity, and Inclusion as our three strong pillars which continue to create a mutually evolving workplace attracting a diverse pool of talent across various cultural and traditional backgrounds. An open atmosphere built on trust with our employees where every employee feels equally valued, encouraged, motivated, heard, supported, and guided in all areas of Stratus ecosystem. A workplace which ensures equal opportunity to one and all.
This in turn creates impactful results and empowering our clients to achieve their goals utilizing our diversified and inclusive taskforce operating across our global delivery centers in India, the US, and the Latin America.
With our Business Value-Driven Delivery Model, we are focused to cultivate a people-and-business-oriented work environment in which all employees in the organization are seen and treated as valuable human resources and business partner at the same time. This culture supports formal and affable relations fairly because this would help people to relate with each other on an open and positive note. At the same time, all tasks and responsibilities are taken seriously.
Our policies and commitment include:
- Treating everyone as a valuable contributor and a business partner for the organization.
- Learning and Respecting each other’s’ emotions, feelings, thoughts, and peculiarities.
- Respecting and valuing others’ time, cultural backgrounds, and responsibilities.
- Ensuring everyone in the organization gets optimum attention and support their work-life balance.
- Accepting, adhering, and following organizational strategies and missions so we all together achieve our long-term goals.
- Business etiquette and ethics.
- Positive, inspiring, and supportive attitude.
As rightly quoted by Marco Bizzarri – Diversity and inclusion, which are the real grounds for creativity, must remain at the center of what we do. And at Stratus, we make every day diligent efforts to practice and incorporate diversity and inclusion values through constant communication and connect with our employees across departments, work locations, job functions and management status and hence, ensuring smooth functioning of remote working culture. The Company firmly believes and aligns that this mutually evolving practice needs to spread and adopted across all offices, departments, teams, individuals, employees and even to external interested parties that may require to understand it and co-ordinate their interactions with the requirements. A culture of this kind that involves personal as well as business relations may not be straightforward to establish, understand and regulate. We perceive this as a symbiotic and mutually growing relationship and association where we as an organization ensure and support our employees to accomplish their aspirations while aligning with our Vision to assure optimal solutions are found, conferred, and agreed upon.
We continue to make progress in building a more diverse workforce. For instance, the number of women in tech roles at Stratus is increasing. This diversifies perspectives, knowledge and beliefs coming from many sources including gender, race, age, national origin, sexual orientation, culture, education, and professional and life experience. Stratus remains committed to diversity and inclusion and always look for ways to scale our impact and innovation as we grow.
We have through our time, effort, company policies and strategies achieved a work environment in which all individuals are treated fairly and respectfully, have equal access to opportunities and resources, and can contribute fully to the organization’s success.
Meet the Authors


Garima Goel
Associate SVP, Program Delivery, Stratus Global Technology Services

Thought Leadership: Exploring Future of Drones in Insurance Industry
Thought Leadership: Exploring Future of Drones in Insurance Industry
By Lavanya Ramani
Drones are more formally known as unmanned aerial vehicles (UAVs). Essentially, a drone is a flying robot that can be remotely controlled or fly autonomously through software-controlled embedded systems, working in conjunction with onboard sensors and GPS. The bird’s eye view offered by drones enables businesses to capture detailed photographs and videos from the sky. This visual data, when analyzed and interpreted, helps businesses to gain intelligence that can be used to make informed decisions. Drone usage within the insurance industry is on the rise. They are used to take photos and capture other data to inform insurance risk assessments and claims. What was once seen as cutting edge is quickly becoming a mainstream technology, especially given the current global pandemic situation.
How are Insurers Using Drones or May Use Drones?
Deploying drones for insurance inspections – When a disaster hits, damages must be assessed swiftly to ensure timely payouts to the insureds. However, accessing the disaster area may be dangerous for adjusters. Even when the situation stabilizes, civil authorities may still pose restrictions to enter the areas. This leads to placing thousands of claims on hold, resulting in business downtime, and increasing dissatisfaction among customers. Drones can enter premises and zoom in on affected areas, capturing first-hand data without disturbing/tampering the scene. Humans can remain at a safe distance and review the transmitted video and photos in real time to assess the impact. And with advanced Geographic information system (GIS) if the weather conditions worsen, the UAV can return safely and notify on-ground personnel.
Accelerating claim adjudication – Insurers are still relegated to getting property and other details through outdated inspection processes that involves drive-by inspections, manually inspecting roofs, or renting expensive machinery like cherry pickers to assess high-rise and multi-level structures. This might result in inefficient data gathering. Insurance companies should start enabling efficient techniques to remain competitive in the market Drones have become a necessary tool of the trade for claim adjusters, as it enables them with better decision-making and eliminate guesstimation. Auto insurers should also look into drones. Instead of having boots on the ground, adjusters can quickly dispatch a drone to investigate a claim filed by a customer. This can speed up claims settlement and improve the customer experience.
Risk monitoring – Drones for insurance claims can be dispatched to monitor disaster prone areas and gather data for giving more accurate quotes to customers. By partnering with government organization, insurance companies can also alert residents about risks and help them minimize losses. On a more granular level, drones equipped with infrared cameras have proven effective at detecting water and air leaks – which has been a complicated and time-consuming process for adjusters to identify it manually. This also boosts the efficiency of the staff by 40 to 50 percent.
Better data for analysis – Drones can equip insurance companies with better data for analysis. Gathering comprehensive first-hand data is crucial to determine fault indicator of an accident. Drones offer a safe and fast way of accessing damage. On-site information can be further enriched with additional location data –weather, road conditions, etc. – to create advanced site maps.
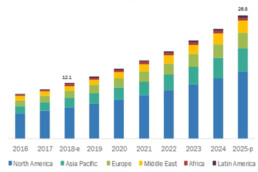
Region Forecast of Drone Usage
North America – North America was the pioneer in using drone technology, especially in insurance and it was the largest region in the drone insurance market in 2020 which also in one way or the other helped industries bounce back quickly.
Asia Pacific – Drones are still emerging in Asia-Pacific Region and is anticipated to have the highest growth during the Forecast Period.
Benefits of Using Drones for Insurers
Comprehensive Data – One of the most substantial factors that make drones unique is high-quality content acquisition. They can easily gather minute details of the location. When done manually, adjusters find it cumbersome to obtain evidences from all angles. Also, the acquired data is considered inefficient and inaccurate. On the other hand, drones collect comprehensive visual information about anything that is insured. This leads to dramatically faster claims processing, better efficacy, and higher profits.
Better transaction processing – The employees shouldn’t put themselves at risk during hands-on inspections at properties, construction sites and other hazardous places. Also, the inspections shouldn’t take long. Insurance companies that use drones receive the information they need 10 times faster than those relying on traditional methods. The costs of gathering the information is also lower.
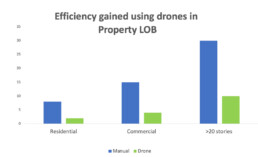
Inspection of Dangerous Areas – It is difficult for emergency responders to visit every affected area to collect the necessary information. Sometimes, reaching the affected place itself is a risky job. Drones can access dangerous areas during inspections, minimizing the risk of harm to the field officers. It can be termed as an insurance for the insurer.
Prevention of Fraudulent Activities – Providing inaccurate information intentionally to gain insurance benefits is a common concern that the insurance companies face. The insured can commit this illegal activity. With drones coming into picture, the chances of such fraudulent activities may be eliminated. Drones can collect and store the data on the cloud. Every department in the insurance company can view, monitor, and inspect the details, leaving no room for any illicit activities.
Augmented accuracy for decision making: Drones also enable adjusters to get very close to a roof, zoom in on questionable areas and analyze details to understand the cause of loss—all without disturbing the scene. This is beneficial when writing reports, as images and video gathered from insurance inspection drones can be easily integrated to present a fuller picture of any claim.

Drone and roof inspections – One of the major uses of drones in the insurance industry is roof inspections. Roofs are indeed the costly parts and insurance companies can only be ready to handle the problems after the damage is clear and easily visible through drones. The high costs of roof maintenance have impacted the budgets of the insurance companies as well. It is due to this reason; many companies avoid promising the damages of the roof if it is older than 20 years. Whenever the roof damages and the owner of the roof files the claim, the insurance industry assigns the roof inspectors who physically climb up the roofs and look for the damages. But nowadays, insurance companies are focusing more on the safety of the insurance inspectors and are oriented towards the use of drones. The best part about the use of drones is that they are helpful for the insurance companies and prevent them from any kind of fraudulent claims.
Identifying the Fraudulent Claim – The housekeeper may apply for insurance for the leaking roof even if it was leaking before the storm. With the help of the drones, the insurers can understand whether the leakage of the roof is due to the storms or not. It helps to eliminate false claims and disputes with customers who submit claims for existing damage.
Real Life Use Cases
Catastrophe
A reinsurance example is the Typhoon Goni catastrophe, where AIG (American international group) used a drone to ease the claims backlog. One of their clients was a factory owner, whose roof was leaking. It was too dangerous to send an inspector up to find the leak, so a drone was used instead.
Roof Inspections
In personal insurance, one of the riskiest and commonest activities that a claims assessor must engage in is roof inspections. This is a hazardous and time-consuming process. It can result in injury to the inspector and take hours navigating around the roof to get a full inspection done.
Using a drone radically reduces the time spent gathering the information, and the inspector does not even have to be on site, as a drone pilot can be sent out instead. An adjuster can triple the number of sites visited from 2 to 3 a day to up to 9 claims.
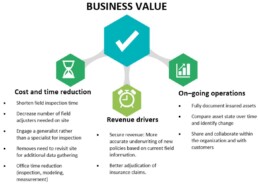
Business Value
Drones are a quantum leap in inspection technology, allowing insurers to capture images of properties that they could never access before. If insurers want to ensure the most accurate assessments and secure the revenues, drones are the only way to go.
Drones Fighting the Pandemic
In a novel coronavirus world, the benefits of using drones is being highlighted even further. Physical assessments are hampered by social distancing and isolation guidelines. Keeping human contact to a minimum has not only become important, but sometimes strictly necessary because of lockdowns or parties — loss adjusters, claims handlers or policyholders — self-isolating. This means that walking through a damaged property with a policyholder may no longer be feasible. 35% of firms in the insurance industry cited to be investing in drone technology, according to a survey conducted by the firm. At a time when many insurers have been badly hit by the pandemic, technology that has the potential to bring operational savings is likely to lure the industry.
Amid the COVID-19 crisis and the looming economic recession, the global drone insurance market is increased from $1.06 billion in 2020 to $1.13 billion in 2021 at a CAGR (Compound Annual Growth Rate) of 6.1%. Since gradually the commercial activities are resuming, the drone operation is also increased. The market is expected to reach $1.41 billion in 2025 at a CAGR of 5.9%. Due to relaxations from the governing bodies like FAA (Federal Aviation Administration) and EASA (The European Union Aviation Safety Agency), demand for drones have emerged in a lot of industries. Going by the trend and the pandemic situation, commercial drones are expected to register higher growth during the forecast period compared to consumer drones.
Challenges of Using Drones in the Insurance Industry
Adopting disruptive technologies of drones in insurance industry always carries a certain amount of regulatory and business risk. For drones to become part of business as usual, the insurance industry will have to address a few drone-related issues.
Aviation regulations – The current FAA rules allow commercial drones to stay in the air during the daytime. They can fly no higher than 400 feet above the ground at a maximum speed of 100 miles per hour and always must remain in the visual line of sight. They cannot fly within 9 kms. of an airport, heliport, or aerodrome. These limitations would restrict an insurer’s ability to use drones for large-scale inspections. But recent waivers now allow limited operations beyond visual line of sight. Due to global covid-19 pandemic, companies expect some progressive rulings for UAVs issued by regulators around the world.
Privacy – Trespassing and operating below navigable airspace can cause legal problems for insurers. Insurance companies must invest in developing rich navigational maps with real-time data to protect them against common-law nuisance claims. Also, insurers must seek permission from insured before conducting a risk assessment of their property. Failing to do so might cause legal trouble.
Casualties and liability – After the drone incident in 2018 at Gatwick airport, England, the public feels unsafe about using drones. Drone crashes, injuries, and casualties have been widely publicized. Therefore, insurers will have to carefully assess the potential damage drone inspections can cause and be prepared to address possible negligence and liability claims.
Corrupted technology – 63% of drone crashes occurs due to technological glitches and not human error. Loss of communication between a drone and the operator is the most common problem. To reduce these risks, the hardware and software must be carefully chosen with a partner who has in depth industry knowledge.
Data leakage and security – Sensitive data can be lost due to a crash or equipment malfunction. Drones, which transmit data in real time, are also exposed to cyber-attacks. The blockchain is one option for managing such sensitive data exchanges, securely transmitting data about a drone’s location, and proximity to restricted zones.
Future of Drones in the Insurance Industry
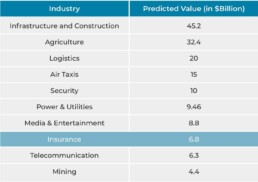
Below is the predicted value of industry sectors globally in 2030.
The insurance industry is very open to embracing new technologies. Drones are sure to rewrite the insurance industry’s standard operating procedures. Areas which insurance industries should try to focus are,
Technical maturity – Technologies play a vital role in the development of insurance companies, contributing to improving the product range and gaining competitive advantages. Drone technology is evolving fast, but many angles still need to be addressed, such as battery life which is still insufficient to perform long-haul flights. Multiple batteries are often required for flights over a large area under investigation.
Return on investments – More use cases are required to prove that drones are more than just a trendy toy. A cost-benefit analysis that shows potential ROI will help convince businesses to use drones in their operations. If a drone isn’t required for frequent use (e.g. only for an annual analysis), ‘drones as a service’ may be a more relevant way to introduce drones. When the human effort is no longer required and drones can fly autonomously and/or in combination with robotics, that’s where real disruption will come in and the use of drones will be faster, safer, more accurate and cheaper.
Market immaturity – Market immaturity is evident on the level of business models. Many insurers are still trying to identify where they’d like to be in the market and what to focus on. With no one-stop shop, industries must build their own knowledge of drones and be able to explain their needs and required drone specifications.
Early stage – Software is still at an early stage and there’s no off-the-shelf software available that fits the needs of most businesses, mainly because professional users want them for niche applications. Businesses are therefore required to develop their own software or at least actively participate in its development. More mature software packages will allow businesses to reach efficiencies, such as higher processing speed, intelligent recognition, and pre-analysis of irregularities.
Source –
https://medium.com/justez/the-future-of-drone-technology-and-insurance-e3965d1ecf1
http://riskandinsurance.com/rise-drones/
https://www.commercialuavnews.com/europe/value-european-drone-market
https://www.carriermanagement.com/news/2016/09/13/158783.html
Meet the Author
Lavanya Ramani
Business Analyst Manager

#ValueLeap with Rating Automation Tool – Stratus Driving Efficiency Gains with Automation
#ValueLeap with PDF Reader Utility – Stratus Driving Innovation with Automation
By Bhanu Regulagedda, Partha Pritam & Garima Goel
Problem Statement:
Rate Testing holds utmost importance for each insurance carrier as it deals with ensuring the accuracy of Premium and financials that the carrier charges to their customers. However, Rate Testing is complex to validate due to below factors:
- Thousands of Testing combinations
- Multiple States and LOB variations
- Multiple level of Input data combinations
It is also practically difficult and challenging to validate all the combination and levels of input data manually since it is time consuming, error prone and expensive.
Proposed Solution Overview:
- Stratus developed in-house Rate automation tool built using Selenium & Java, to automate the rate validation steps.
- This tool compares the Individual coverage Premium and Total Policy premium of a Policy with premium generated in Rating algorithm sheets provided by the actuaries.
- Generate user friendly reports to check the premium mismatches along with insights to the premium matches for easy understanding
Solution Details:
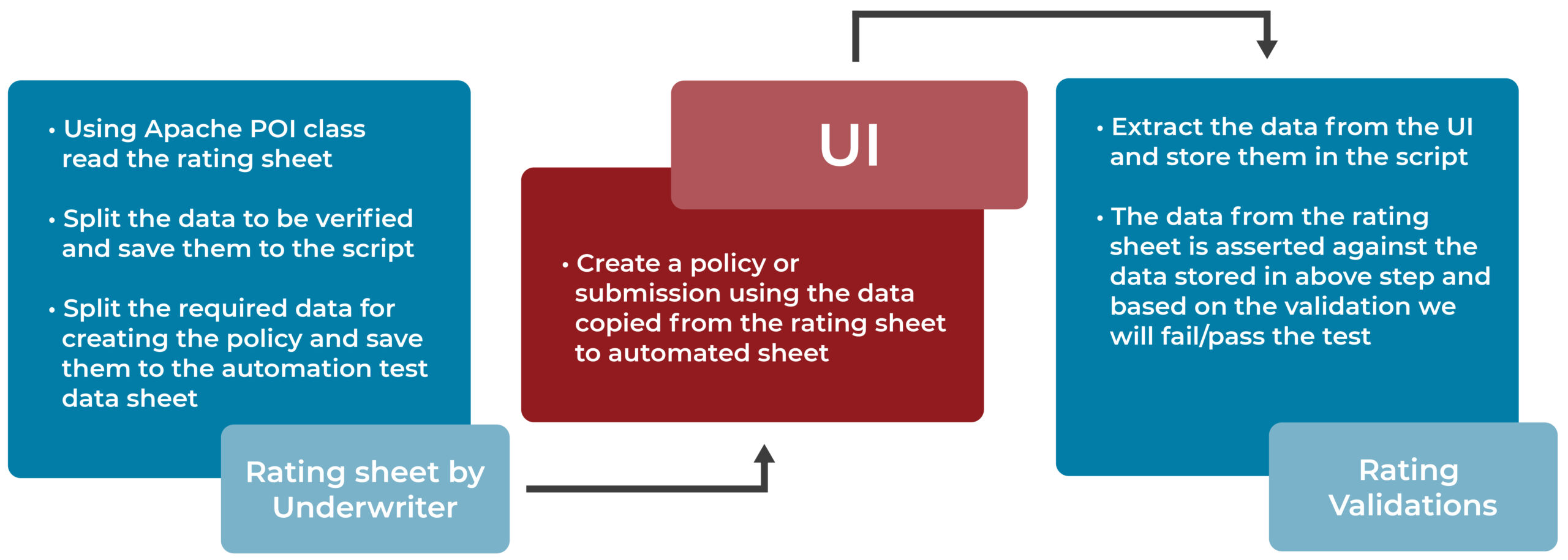
Step 1: Identifying the Rating Test scenarios
- Functional QA team identifies the Rating Test scenarios for automation
- Identify Test Scenarios covering multiple levels of data combinations which cannot be covered via manual validation
Step 2: Prepare the Test Data Sheet
- Populate Rating algorithm worksheets (provided by actuaries) with diversified input data combinations
- Create unique Rating algorithm sheet for each scenario
- Use selenium scripts to read all the premium bearing fields and pull their values from Rating algorithm sheet to another spreadsheet called Test Data worksheet
- Add the data input for fields those are non- premium bearing but mandatory for quoting the transaction in Test data spread sheet
Step 3: Execute the automation script
- Selenium automation script inputs these data into GW PolicyCenter UI and Quote the transactions being tested (Submission, Renewal, Rewrite etc.).
Step 4: Result validation
- Automation Script compares both individual Coverage premium and Total Policy premium stored in the test data sheet with Premium generated in PolicyCenter UI and reports the comparison result.
Understanding of Solution Architecture:
#ValueLeap – Business Value Delivered
- 40% to 50% reduction in manual effort through Parallel bulk execution of automation scripts bringing efficiency
- Increased test coverage helping to enhance the scope of test scenarios
- Accuracy and consistency in validation of premiums and financials
- Reduced defect leakage caused due to manual comparison
- Reduced execution timelines
- Easy and user-friendly end result reporting
Meet the Authors
Garima Goel
Associate SVP, Program Delivery, Stratus Global Technology Services

Metaverse - The Gateway to a Virtual World
Metaverse - The Gateway to a Virtual World
By Vijay Yadav
Virtual Reality (VR) and Augmented Reality (AR) have been the mechanism to combine real and virtual worlds to provide an immersive user experience. User has to use the specially designed headsets to experience the VR/AR created environment. However, the experience has been limited to as watching the virtual world from outside.
Metaverse is an emerging concept which will provide the mechanism to become the part of virtual world i.e., Users will be able to enter the virtual world with their digital Avatars and interact with their virtual surroundings. Consider the scenario of attending a meeting as digital Avatar with your colleagues while physically sitting in your home. There are many Use Cases like attending a concert or sport event, shopping at retail store or attending classes can be achieved while physically away.
While it will take time before the objectives of Metaverse are met completely, many organizations have already started building solutions around it. For example, Travis Scott (American Rapper) held a virtual concert in video game Fortnite or Microsoft working on a feature for Teams called Mesh, which will allow the people in different physical locations to connect in virtual meeting room and experience the vibe of physical meeting. Social media giant Meta (formerly known as Facebook) is moving aggressively to implement Metaverse solutions to provide real-life experience in virtual world. This is evident from the Mark Zuckerberg address at Connect 2021 posted below.
Further details on Metaverse can be found at below links:
https://en.wikipedia.org/wiki/Metaverse
https://www.wsj.com/story/what-is-the-metaverse-the-future-vision-for-the-internet-ca97bd98
Meet the Author


Case Study – Stratus continues to deliver Happy Guidewire Clients
Case Study – Stratus continues to deliver Happy Guidewire Clients
By Midhilesh Thokachichu & Garima Goel
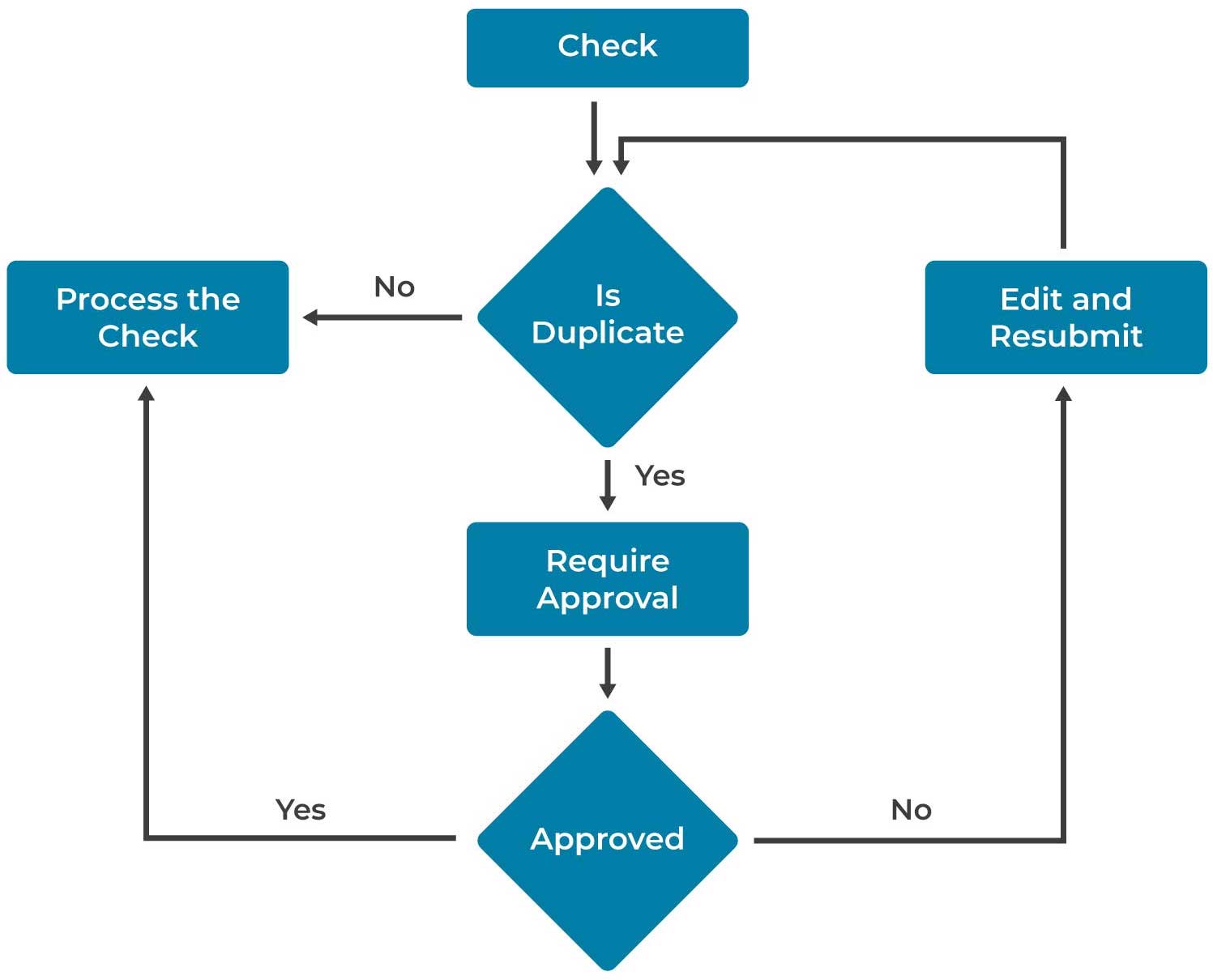
What are Duplicate Checks?
When a check is created for the same payee and with the same amount as other checks that already exists on a claim, then the newly created check is considered as a duplicate check.
Problem Statement:
Duplicate checks when exist on a claim, it will get processed like a non-duplicate check and hence there is probability to pay the claimant/vendor (Payee) more than once. So, the ClaimCenter needs a way to identify the duplicate checks that are being created on a claim and get them approved by the Supervisor (of the assigned Claim Adjuster) before processing them.
Proposed Solution:
Enhanced the ClaimCenter financials functionality and created a new workflow to monitor the duplicate checks without changing the existing OOTB workflow which validates the authority limits of the check created by the user. Now the both the workflows can co-exist and ensure that the payments made on a claim are accurate and not duplicate.
Implemented Solution Workflow:
#ValueLeap – Business Value Delivered
- Enhanced the ClaimCenter financials functionality to make sure that the payments being made are accurate, seamless and efficient.
- Eliminate the risk of making a payment that has already been done.
- Saving the effort and time of manually analysing duplicate payments after they are processed in ClaimCenter
- Supervisors will be notified of the payments that are being made on a claim.
- Delivering Happy Client saving time and cost.
Meet the Authors
